Decision trees are a fundamental concept in the field of machine learning. They provide a simple yet powerful way to make decisions and solve complex problems. In this article, we will explore the concept of decision trees, understand how they work, and delve into their applications. So, let’s dive in and unravel the intriguing world of decision trees!
Introduction to Decision Trees
Decision trees are a popular supervised learning algorithm used in machine learning for both classification and regression tasks. They mimic the structure of a flowchart, where each internal node represents a feature or attribute, each branch represents a decision, and each leaf node represents an outcome or prediction.
How Decision Trees Work
Decision trees work by recursively partitioning the data based on the values of the features. The goal is to create homogeneous subsets of the data at each internal node, where the instances within each subset share similar characteristics. This process continues until a stopping criterion is met, such as reaching a maximum depth or purity.
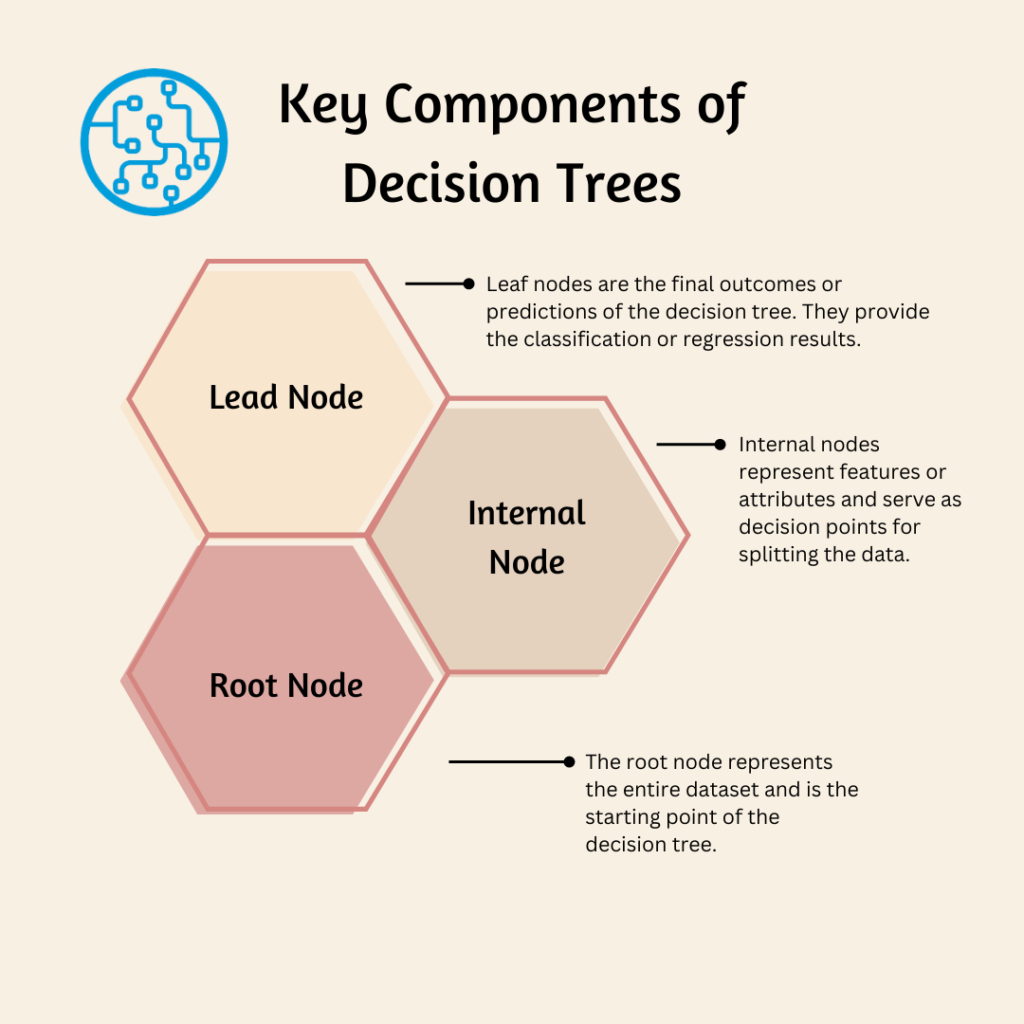
Key Components of Decision Trees
There are three key components of decision trees:
a) Root Node
The root node represents the entire dataset and is the starting point of the decision tree.
b) Internal Nodes
Internal nodes represent features or attributes and serve as decision points for splitting the data.
c) Leaf Nodes
Leaf nodes are the outcomes or predictions of the decision tree. They provide the classification or regression results.
Building Decision Trees
The process of building decision trees involves selecting the best feature to split the data at each internal node. This is done by evaluating different splitting criteria, such as information gain, Gini impurity, or entropy.
Splitting Criteria in Decision Trees
Splitting criteria are used to determine how to divide the data at each internal node. Popular splitting criteria include:
a) Information Gain
Information gain measures the reduction in entropy or impurity achieved by splitting the data based on a particular feature.
b) Gini Impurity
Gini impurity measures the probability of misclassifying a randomly chosen element if it were labeled randomly according to the distribution of labels in the subset.
Handling Overfitting in Decision Trees
Decision trees tend to overfit the training data, which can lead to poor generalization on unseen data. To address this issue, techniques like pruning, setting a minimum number of samples per leaf, or using ensemble methods like random forests can be employed.

Advantages of Decision Trees
Decision trees offer several advantages in machine learning:
- Easy to understand and interpret.
- Can handle both categorical and numerical features.
- Require minimal data preprocessing.
- Can capture non-linear relationships between features and the target variable.
- Provide feature importance rankings.
Limitations of Decision Trees
Despite their advantages, decision trees also have limitations:
- Prone to overfitting.
- Sensitive to small changes in the training data.
- Can create biased trees if the data is imbalanced.
- May not generalize well to unseen data.
- Not suitable for capturing complex relationships or interactions.
Decision Trees in Classification Problems
In classification problems, decision trees can be used to predict the class or category to which an instance belongs. Each leaf node represents a class, and the path from the root to a leaf node defines a set of rules for classifying instances.
Decision Trees in Regression Problems
In regression problems, decision trees can be used to predict continuous or numerical values. The predicted value at each leaf node is the average or majority value of the target variable for the instances in that leaf node.
Ensemble Methods and Decision Trees
Ensemble methods combine multiple decision trees to improve predictive performance. Random forests, gradient boosting, and AdaBoost are some popular ensemble methods that leverage the power of decision trees.
Decision Trees in Real-World Applications
Decision trees find applications in various domains, including:
- Finance and banking for credit scoring and fraud detection.
- Healthcare for disease diagnosis and prognosis.
- Customer relationship management for customer segmentation.
- Manufacturing for quality control and fault detection.
- Marketing for target audience selection and campaign optimization.
Evaluating Decision Trees
Several evaluation metrics are used to assess the performance of decision trees, such as accuracy, precision, recall, F1 score, and area under the receiver operating characteristic curve (AUC-ROC).
Best Practices for Using Decision Trees
To maximize the effectiveness of decision trees, it is important to follow these best practices:
- Perform feature engineering and data preprocessing.
- Handle missing values appropriately.
- Tune hyperparameters to find the optimal tree size.
- Use cross-validation to assess the model’s performance.
- Regularize the decision tree to avoid overfitting.
Conclusion
Decision trees are a powerful tool in machine learning, offering a transparent and interpretable approach to decision-making. They are widely used for classification and regression tasks, providing valuable insights and predictions. Understanding the key concepts and techniques associated with decision trees is essential for any data scientist or machine learning practitioner.
Frequently Asked Questions
Q1: Are decision trees only used in machine learning?
Decision trees are primarily used in machine learning but have applications in other fields as well, such as operations research and decision analysis.
Q2: Can decision trees handle missing values?
Yes, decision trees can handle missing values by using techniques like surrogate splits or imputation methods.
Q3: Are decision trees prone to overfitting?
Yes, decision trees can be prone to overfitting, especially when the tree becomes too deep or complex. Regularization techniques like pruning or setting a maximum depth can help mitigate this issue.
Q4: How can decision trees handle categorical features?
Decision trees can handle categorical features by employing techniques like one-hot encoding or label encoding to convert them into numerical representations.
Q5: Can decision trees capture non-linear relationships?
Yes, decision trees can capture non-linear relationships between features and the target variable by recursively splitting the data based on different thresholds.
Feedback
In this article, we explored decision trees in machine learning, understanding their working, components, building process, splitting criteria, advantages, and limitations. We also discussed their applications, evaluation, and best practices, and answered frequently asked questions. Decision trees are an asset in the field of machine learning, empowering data scientists to make informed decisions and gain valuable insights from complex datasets. So go ahead and embrace the power of decision trees in your machine-learning endeavors!
